![]() SELFHTML/Quickbar
SELFHTML/Quickbar
![]() Internationalisierung
Internationalisierung
Die beiden Grundeinheiten in jedem heutigen Computer sind die Einheiten Bit und Byte. Ein Byte ist bei den heute üblichen Systemen als Folge von 8 Bit definiert (man spricht auch von Octets). Da jedes Bit zwei Zustände haben kann, nämlich 0 oder 1 bzw. ja oder nein, lassen sich mit einer Folge von 8 Bit genau 256 (= 2 hoch 8) unterschiedliche Zustände realisieren. Ein Byte kann also 256 unterschiedliche Werte haben. Da im Computer immer auch die 0 dazugehört, können in einem Byte dezimal ausgedrückt Werte zwischen 0 und 255 stehen.
Wenn ein laufendes Programm im Computer eine Datei zeichenweise in den Arbeitsspeicher einliest, stehen im Arbeitsspeicher anschließend nur Byte-Werte. Wenn also ein WWW-Browser eine HTML-Datei in den Arbeitsspeicher einliest, besteht die Datei dort aus nichts anderem als Byte-Werten. Von Zeichen unseres Alphabets ist auf dieser Ebene noch keine Rede. Damit aus den Byte-Werten lesbare Zeichen werden, die sich am Bildschirm darstellen lassen, braucht es eine Konvention, die festlegt, welcher Byte-Wert als welches Zeichen dargestellt werden soll. Diese Aufgabe haben die sogenannten Zeichensätze. Zeichensätze sind Tabellen, die einem Byte-Wert ein Zeichen zuordnen, das in unseren Schriftkulturen eine Bedeutung hat.
Die Zeichensätze sind EDV-historisch gewachsene Gebilde. Bis zum Aufkommen der Personal Computer benutzten viele Rechner noch 7 Bit lange Grundeinheiten, mit denen sich nur 128 unterschiedliche Zustände darstellen lassen. Noch früher waren es auch mal 6 und 5 Bit lange Grundeinheiten. Auf der 7 Bit langen Grundeinheit beruhten die ersten Zeichensätze, die historisch den Durchbruch schafften: der ASCII-Zeichensatz und der EBCDIC-Zeichensatz. Dabei setzte sich vor allem der ASCII-Zeichensatz durch, weil er im erfolgreichen Unix-Betriebssystem und in den aufkommenden Personal Computern zum Einsatz kam.
Beim ASCII-Zeichensatz sind die ersten 32 Zeichen für Steuerzeichen reserviert, etwa für Tastatur-Impulse wie Zeilenumbruch. Die Zeichen zwischen 32 und 127 sind darstellbare Zeichen, darunter alle Ziffern, Satzzeichen und Buchstaben, die ein Amerikaner so braucht (denn der ASCII-Zeichensatz kommt natürlich aus den USA).
Lange Zeit war ASCII der einzige verbreitete Standard. Da die neueren Computer aber 8 Bits hatten, war es folgerichtig, für die Werte zwischen 128 und 255 neue Verwendungszwecke zu finden. Dabei entwickelten sich jedoch proprietäre Lösungen. MS DOS beispielsweise benutzt einen "erweiterten ASCII-Zeichensatz", der aber nicht viel mehr ist als eine schöne Umschreibung für die Microsoft-eigene Belegung der Zeichen 128 bis 255 speziell für die Bedürfnisse von MS DOS.
Um auch hierfür einen Standard zu schaffen, ersann die amerikanische Standardisierungs-Organisation den ANSI-Zeichensatz. Dieser Zeichensatz übernimmt für die Zeichen 0 bis 127 den ASCII-Zeichensatz und definiert für die Werten zwischen 128 und 255 etliche Sonderzeichen, darunter wichtige Alphabetzeichen verbreiteter Sprachen, etwa deutsche Umlaute, französische Accent-Zeichen oder spanische Zeichen mit Tilde. Dazu kamen diverse verbreitete kaufmännisch-/wissenschaftliche Zeichen.
Der Bedarf an international gültigen Zeichensätzen wird jedoch immer größer. Ein Versuch, ein solches Set von Zeichensätzen zu etablieren, stellt die ![]() iso-8859-Familie dar. HTML unterstützt mittlerweile die Möglichkeit, all diese Zeichensätze zu verwenden.
iso-8859-Familie dar. HTML unterstützt mittlerweile die Möglichkeit, all diese Zeichensätze zu verwenden.
|
|
Ein Beispiel soll das Prinzip der Zeichensätze verdeutlichen. Die folgende Abbildung zeigt zwei Zeichensätze: den MS-DOS-Zeichensatz und den ANSI-Zeichensatz, den z.B. MS Windows als Voreinstellung verwendet.
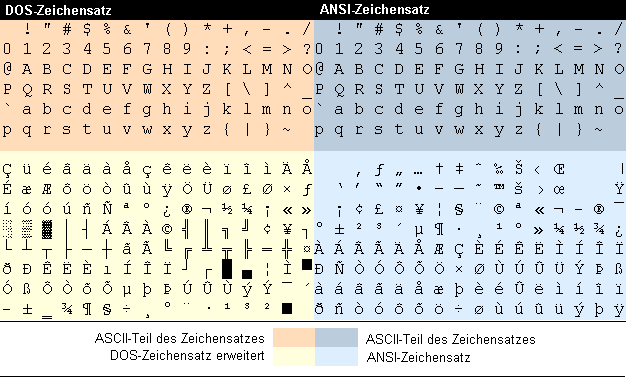
Der Abbildung können Sie entnehmen, daß die oberen Teile (dunkler) beider Zeichensätze identisch sind, da beide Zeichensätze den ASCII-Zeichensatz für die ersten 128 Zeichen übernehmen (die ersten 32 Zeichen fehlen in der Abbildung, da es sich bei diesen Zeichen um Steuerzeichen handelt, die nicht abbildbar sind). Die unteren Teile (heller) sind dagegen unterschiedlich. Wo im ANSI-Zeichensatz beispielsweise ein kleines deutsches ü liegt, bietet der erweiterte DOS-Zeichensatz ein hochgestelltes S an.
Wenn Sie mit MS Windows arbeiten, können Sie das selbst ausprobieren: erzeugen Sie unter MS Windows mit einem ANSI-Texteditor (z.B. Notepad) eine leere Datei: tippen Sie einfach so etwas wie "ääääööööüüüü" ein. Die Eingaben speichern Sie unter einem Dateinamen ab. Anschließend rufen Sie die DOS-Eingabeaufforderung auf und geben edit ein. Dann öffnet sich der DOS-Editor. Damit öffnen Sie die zuvor unter Windows abgespeicherte Datei. Nun können Sie sehen, was der Zusammenhang zwischen Byte und Zeichensatz ist: es werden zwar genau so viele Zeichen angezeigt als unter MS Windows, aber es sind andere Zeichen. Der Grund ist, daß im Arbeitsspeicher immer nur Byte-Werte stehen. Was ein Programm jedoch daraus macht, hängt davon ab, welchen Zeichensatz es benutzt.
Das Beispiel zwischen dem MS-DOS-Zeichensatz und dem ANSI-Zeichensatz wurde hier bewußt ausgewählt, da es sich an ein und demselben Rechner testen läßt. Das Beispiel soll aber vor allem auch dazu ermuntern, tiefer in die Geheimnisse der Zeichensätze einzusteigen und sich besonders an die Regeln der ![]() Verwendung von Zeichensätzen und Unicodes in HTML zu halten.
Verwendung von Zeichensätzen und Unicodes in HTML zu halten.
|
|
Zeichensätze decken einzelne Schriftkulturen und damit verbundene Sprachen oder Sprachfamilien ab. Problematisch wird es, wenn mehrsprachige Dokumente erstellt werden sollen, die Schriften ganz unterschiedlicher Zeichensätze enthalten. Auch für nicht-alphabetische Schriftkulturen sind Zeichensätze ungeeignet. In unseren Zeiten der Globalisierung wird es jedoch immer wichtiger, für solche Probleme eine standardisierte EDV-technische Lösung zu finden, die sich auf den verschiedensten Computersystemen durchsetzt. Eine solche Lösung gibt es auch schon: das ![]() Unicode-System. Unicode soll langfristig das heute übliche System der Zeichensätze ablösen.
Unicode-System. Unicode soll langfristig das heute übliche System der Zeichensätze ablösen.
Ferner muß bei so einem Ansatz das Problem gelöst werden, wie sich die numerischen Werte mit Hilfe von Schriftarten in anzeigbare oder druckbare Zeichen umsetzen lassen.
|
|
Schriftarten sind Beschreibungsmodelle, um auf Ausgabemedien wie Bildschirm oder Drucker Zeichen abzubilden. Jedes heute übliche Betriebssystem enthält sogenannte Systemschriften. Das sind Schriftarten, die auf jeden Fall genau die Zeichen enthalten, die in dem ![]() Zeichensatz definiert sind, auf dem das Betriebssystem per Voreinstellung basiert. Unter MS Windows gibt es beispielsweise eine solche Schriftart namens "System". Daneben gibt es auf modernen Rechnern definierte Schnittstellen für beliebige Schriftarten. Verbreitet ist z.B. die Adobe-Schnittstelle für Schriftarten ("PostScript"). Unter MS Windows kommt eine eigene Schnittstelle hinzu ("TrueType").
Zeichensatz definiert sind, auf dem das Betriebssystem per Voreinstellung basiert. Unter MS Windows gibt es beispielsweise eine solche Schriftart namens "System". Daneben gibt es auf modernen Rechnern definierte Schnittstellen für beliebige Schriftarten. Verbreitet ist z.B. die Adobe-Schnittstelle für Schriftarten ("PostScript"). Unter MS Windows kommt eine eigene Schnittstelle hinzu ("TrueType").
Solche Schriftarten können auf die zur Verfügung stehenden Byte-Werte beliebige Darstellungsmuster legen. So gibt es auch Schriftarten wie WingDings oder ZapfDingbats, die fast nur Symbole und Icons enthalten. Wichtig sind jedoch vor allem auch Schriftarten, die zwar ansprechend aussehen, aber gleichzeitig einen bestimmten Zeichensatz unterstützen, d.h. alle Zeichen dieses Zeichensatzes darstellen, und zwar genau auf den Byte-Werten, die im Zeichensatz dafür vorgesehen sind. Nur durch solche Schriftarten wird es möglich, festgelegte Zeichensätze in eine grafisch darstellbare Form zu bringen. Die folgende Abbildung zeigt ein Beispiel für diesen Zusammenhang:

Solche Schriftarten bleiben jedoch zeichensatzorientiert. Auf den Ansatz von ![]() Unicode ist das Prinzip zeichensatzorientierter Schriftarten kaum übertragbar.
Unicode ist das Prinzip zeichensatzorientierter Schriftarten kaum übertragbar.
Für den Einsatz im WWW sind herkömmliche Schriftarten wie Adobe- oder Truetype-Schriftarten nicht geeignet, da sie plattformspezifisch sind. Mittlerweile gibt es jedoch Ansätze zur Lösung dieses Problems. Es gibt plattformunabhängige Schriftarten, die Sie mit Hilfe entsprechender Befehle auch direkt in HTML einbinden können. Auf diese Weise können Sie nicht nur eine Schriftart erzwingen in der Hoffnung, daß diese beim Anwender vorhanden ist, sondern Sie liefern die Schriftart mit Ihren HTML-Dateien gleich mit. Deshalb spricht man dabei auch von ![]() downloadbaren Schriftarten.
downloadbaren Schriftarten.
|
|
Da die Computerindustrie historisch gesehen in den USA und Europa entstand, bauen die heutigen Hardware-Systeme und Betriebssysteme auf Prinzipien auf, die zunächst als selbstverständlich galten. Wenn Sie in einem Textverarbeitungsprogramm einen Text tippen, wandert der Cursor beim Schreiben von links nach rechts. Automatische Zeilenumbrüche erfolgen nach typischen Begrenzerzeichen westlicher Sprachen wie Leerzeichen oder Silbentrennstrich.
Es gibt jedoch etliche Schriftkulturen, die eine andere Schreibrichtung als die unsrige haben. Dazu gehören etwa die arabische Schrift, die hebräische Schrift oder die fernöstlichen Schriftkulturen. Um solche Schriftkulturen auf Computern abzubilden, ist eine zusätzliche, systemnahe Software erforderlich. Denn es gilt nicht nur, die Schriftelemente abzubilden, sondern auch die Editierrichtung bei der Texteingabe und die Ausgaberichtung auf Medien wie Bildschirm oder Drucker an die Schreibrichtung der entsprechenden Schriftkultur anzupassen.
|
| |
| weiter: |
|
| zurück: |
|